面试 提取 精2
## 事务的七种传播行为
- propagation_required:如果当前没有事务,就新建一个事务,如果已经存在一个事务中,则加入到这个事务中,(最常见的选择)
- propagation_supports:支持当前事务,如果没有当前事务,就以非事务方法执行。
- propagation_mandatory:使用当前事务,如果没有当前事务,就抛出异常。
- propagation_required_new:新建事务,如果当前存在事务,就把当前事务挂起。
- propagation_not_supported:以非事务方式执行操作,如果当前存事务,就把当前事务挂起。
- propagation_never:以非事务方式执行操作,如果当前事务存在则抛出异常。
- propagation_nested:如果当前存在事务,则在嵌套事务执行。如果当前没有事务,则执行与propagation_required类似的操作。
Spring默认的事务传播行为是PROPAGATION_REQUIRED,它适用于绝大多数情况。
## 并发事务带来哪些问题?
- 脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到
数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提
交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确
的。
- 幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接
着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了
一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
- 不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结束
时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改
导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样
的情况,因此称为不可重复读。
不可重复读和幻读区别:
不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者
删除比如多次读取一条记录发现记录增多或减少了。
## 事务隔离级别有哪些?MySQL的默认隔离级别是?
SQL 标准定义了四个隔离级别:
- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会
导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻
读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务
自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执
行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻
读
MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)。我们可以通过
SELECT @@tx_isolation; 命令来查看
这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 REPEATABLE-READ(可重读)
事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如
SQL Server) 是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重
读) 已经可以完全保证事务的隔离性要求,即达到了 SQL标准的 SERIALIZABLE(可串行化) 隔离级
别。因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 READ�COMMITTED(读取提交内容) ,但是你要知道的是InnoDB 存储引擎默认使用 REPEAaTABLE�READ(可重读) 并不会有任何性能损失。
InnoDB 存储引擎在 分布式事务 的情况下一般会用到 SERIALIZABLE(可串行化) 隔离级别。
## redis的数据类型,以及每种数据类型的使用场景
回答:一共五种
(一)String
这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计
数功能的缓存。
(二)hash
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,
就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟
出类似session的效果。
(三)list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基
于redis的分页功能,性能极佳,用户体验好。本人还用一个场景,很合适—取行情信息。就也是个生产
者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。
(四)set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去
重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去
重,再起一个公共服务,太麻烦了。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
(五)sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N
操作。
## redis的过期策略以及内存淘汰机制
在redis.conf中有一行配置 maxmemory-policy volatile-lru 该配置就是配内存淘汰策略的
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据,新写入操作会报错
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和
volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
## Redis 为什么是单线程的
官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内
存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的
方案了(毕竟采用多线程会有很多麻烦!)Redis利用队列技术将并发访问变为串行访问
1)绝大部分请求是纯粹的内存操作(非常快速)2)采用单线程,避免了不必要的上下文切换和竞争条
maxmemory-policy volatile-lru
件
## Redis 常见性能问题和解决方案
(1) Master 最好不要做任何持久化工作,如 RDB 内存快照和 AOF 日志文件
(2) 如果数据比较重要,某个 Slave 开启 AOF 备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性, Master 和 Slave 最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即: Master <- Slave1 <- Slave2 <-Slave3
## MQ
### 为什么使用MQ
核心:解耦,异步,削峰
### MQ优缺点
优点
- 解耦,异步,削峰
缺点
- 系统可用性降低
系统引入的外部依赖越多,越容易挂掉。万一 MQ 挂了,MQ 一挂,整套系统崩溃,你不就完了?
- 系统复杂度提高
硬生生加个 MQ 进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的
顺序性?问题一大堆
- 一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那
里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了
### RabbitMQ如何保证消息的可靠传输
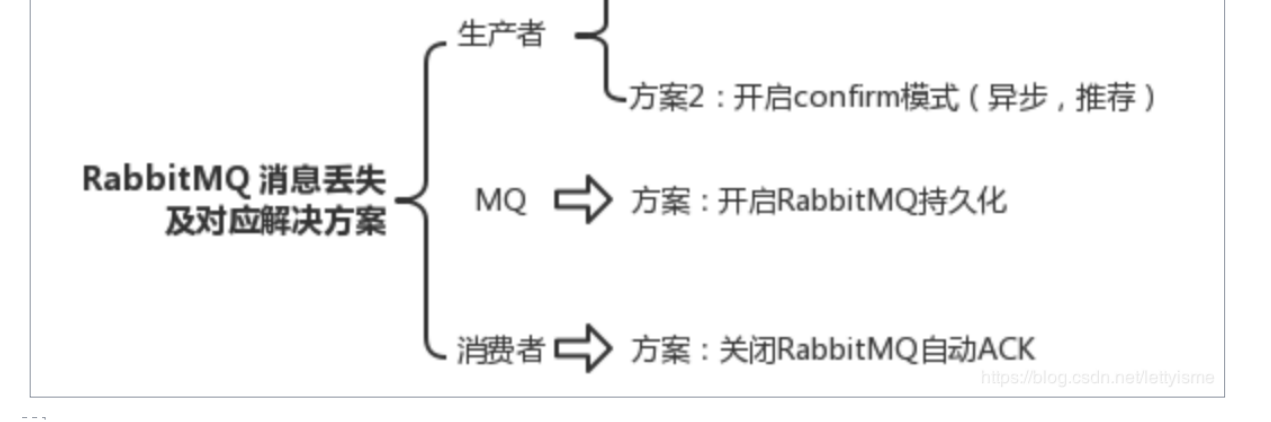
- 生产者发送数据
1. 可以开启confirm模式,在生产者那里设置开启confirm模式之后
2. 写入了 RabbitMQ 中,RabbitMQ 会 异步回调 给你回传一个ack消息,告
诉你说这个消息 ok 了
3. 如果超过一定时间还没接收到这个消息的回调,那么你可以重发
4.
- MQ中丢失
1.就是 RabbitMQ 自己弄丢了数据,这个你必须开启 RabbitMQ 的持久化,就是消息写入之后会持久化到磁盘,哪怕是 RabbitMQ 自己挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢
- 消费端丢失
1. 简单来说在 在你接信息时,mq会自动ack(发一条信息给mq已消费),
我们需要取消自动ack,先处理消息完成后,通过一个 api 来调用ack.
2. 这个时候得用 RabbitMQ 提供的ack机制,简单来说,就是你关闭 RabbitMQ 的自动ack,可以通过一个 api 来调用就行,然后每次你自己代码里确保处理完的时候,再在程序里ack一把。这样的话,如果你还没处理完,不就没有ack?