其他-面试题
<span id="wtl-1-1"></span> <span id="wtl-2-1"></span> <span id="wtl-11-1"></span> <span id="wtl-12-1"></span>
## 关键字
- [final](#wtl-1) --------- [static](#wtl-2)
- [String、StringBuffer、StringBuilder的区别](#wtl-11)
- [String 类的常用方法都有那些](#wtl-12)
- [流:字节流和字符流哪个好?](#wtl-04011)
- [三次握手的概念? ](#wtl-04013)
- [JSP九大内置对象? ](#wtl-04014)
<span id="wtl-21-1"></span>
## 集合
- [list -set -map 及其实现类](#wtl-21)
<span id="wtl-3-1"></span>
## 线程
- [线程的创建方式有几种](#wtl-3)
<span id="wtl-4-1"></span>
## java锁
- [AQS 模板模式](#wtl-4)
- [sleep()和wait()有什么区别](#wtl-04012)
<span id="wtl-5-1"></span> <span id="wtl-6-1"></span> <span id="wtl-7-1"></span>
## spring ----springMVC ----SpringBoot
- [spring @autowired @resource注解](#wtl-5)
- [Spring-bean的循环依赖以及解决方式](#wtl-6)
- [Spring框架IOC和AOP](#wtl-7)
- [Spring什么情况下事务会失效](#wtl-04028)
- [Spring框架中都用了哪些设计模式](#wtl-04031)
---
- [SpringMVC请求处理流程](#wtl-04027)
---
- [SpringBoot有哪些优点](#wtl-040210)
- [SpringBoot的自动配置原理?](#wtl-040211)
<span id="wtl-22-1"></span><span id="wtl-23-1"></span><span id="wtl-24-1"></span><span id="wtl-25-1"></span>
## 常用的设计模式(23种)
- [单例模式](#wtl-22)
- [观察者模式](#wtl-23)
- [装饰者模式](#wtl-24)
- [适配器模式](#wtl-25)
<span id="wtl-30-1"></span>
## mysql 数据库
- [数据库索引有哪几种类型?](#wtl-30)
- [索引的优点-缺点](#wtl-04025)
- [mysql 数据结构-及其他数据结构](#wtl-31)
- [mysql性能优化调优](#wtl-33)
- [SQL语句优化 ](#wtl-04026)
<span id="wtl-32-1"></span>
## redis 等中间件
- [redis](doc:c6tRSP1V)
- [redis的几种数据结构 ](#wtl-32)
---
---
---
---
---
<span id="wtl-04012">开始
-------------------------------</span>
==sleep()和wait()有什么区别==
- sleep 是线程类(Thread)的方法,导致此线程暂停执行指定时间,给执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复。调用sleep 不会释放对象锁。
- wait 是Object 类的方法,对此对象调用wait 方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify 方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入运行状态。
- 相同点:
- 这两个方法都能使线程进入阻塞状
- 不同点:
- sleep()方法是Thread类中的静态方法;而wait()方法是Object类中的方法;
- sleep()方法可以在任何地方调用;而wait()方法只能在同步代码块或同步方法中使用(即使用synchronized关键字修饰的);
- 这两个方法都在同步代码块或同步方法中使用时,sleep()方法sleep 不会释放对象锁;而wait()方法则会释放对象锁;
[--------------------------结束](#wtl-4-1)
<span id="wtl-33">开始
-------------------------------</span>
==mysql性能优化调优==
- 可以在建表的时候,为了获取更好的性能,将表中的字段长度设的尽可能的小。
- 尽可能的把字段设置成NOT NULL,这样在执行查询的时候,数据库不用去比较NULL值。
- 对于部分的文本字段,例如“性别”或者“民族”,我们就可以用enum(int)来定义
- 索引应建立在那些将用于JOIN,WHERE判断和ORDERBY排序的字段上。尽量不要对数据库中某个含有大量重复的值的字段建立索引。
- like语句操作like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
- 不使用<>操作 id<>3可使用id>3 or id<3来代替。
[--------------------------结束](#wtl-30-1)
<span id="wtl-32">开始
-------------------------------</span>
==redis 等中间件==

[--------------------------结束](#wtl-32-1)
<span id="wtl-31">开始-------------------------------</span>
==mysql 数据结构-及其他数据结构==
- B+树 ==mysql采用的数据结构==
- B+树相比B树,新增叶子节点与非叶子节点关系,叶子节点中包含了key和value,非叶子节点中只是包含了key,不包含value。
- b+树在b树的基础上增加了叶子节点,将所有的节点数据按一定的顺序使用链表连接, 从而范围查询效率非常高。
- Hash算法
- 哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。
- 也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
- 优点:查找可以直接根据key访问
- 缺点: 不能进行范围查找(因为底层数据结构是散列的,无法进行比较大小)
- 二叉树算法
- 如何二叉树是将首次插入的作为根节点,将后面的值与根节点比较,小的在左边,大的在右边。
- 如果首次插入的根节点是最小的,就会造成查询效率变低,所以需要引入平衡二叉树。
- 平衡二叉树算法
- 优点:平衡二叉树算法基本与二叉树查询相同,效率比较高
- 缺点:插入操作需要旋转,支持范围查询(回旋效率低),且如果树的高度越高,查询IO的次数越多
- B树
- B树概括来说是一个节点可以拥有多于2个子节点的二叉查找树。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。普遍运用在数据库和文件系统。
- 因为B树一个节点可以对应多个元素 ,是在平衡二叉树结构中减少了树的高度,所以B树数据结构相比平衡二叉树数据结构实现减少磁盘IO的操作,范围查询效率依然不高。
[--------------------------结束](#wtl-30-1)
<span id="wtl-30">开始-------------------------------</span>
==索引有哪几种类型?==
- 主键索引: 数据列不允许重复,不允许为NULL,一个表只能有一个主键。
- 唯一索引: 数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。
- 普通索引: 基本的索引类型,没有唯一性的限制,允许为NULL值。
- 全文索引:是目前搜索引擎使用的一种关键技术。
> 索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表。索引的原理很简单,就是把无序的数据变成有序的查询

[--------------------------结束](#wtl-30-1)
<span id="wtl-24">开始-------------------------------</span>
==装饰者模式==
- 对已有的业务逻辑进一步的封装,使其增加额外的功能
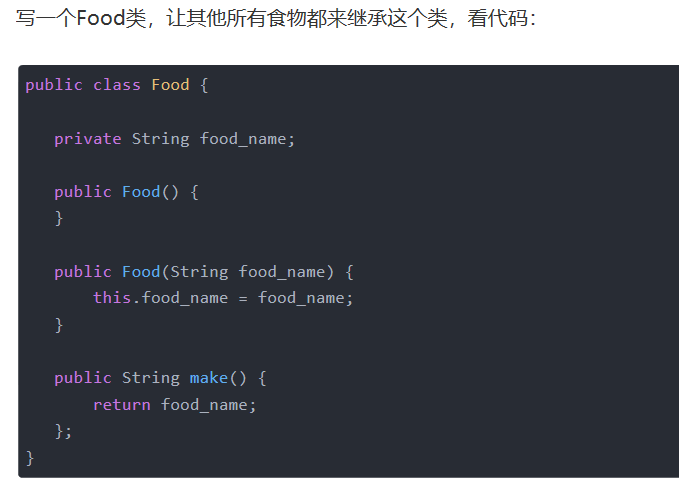
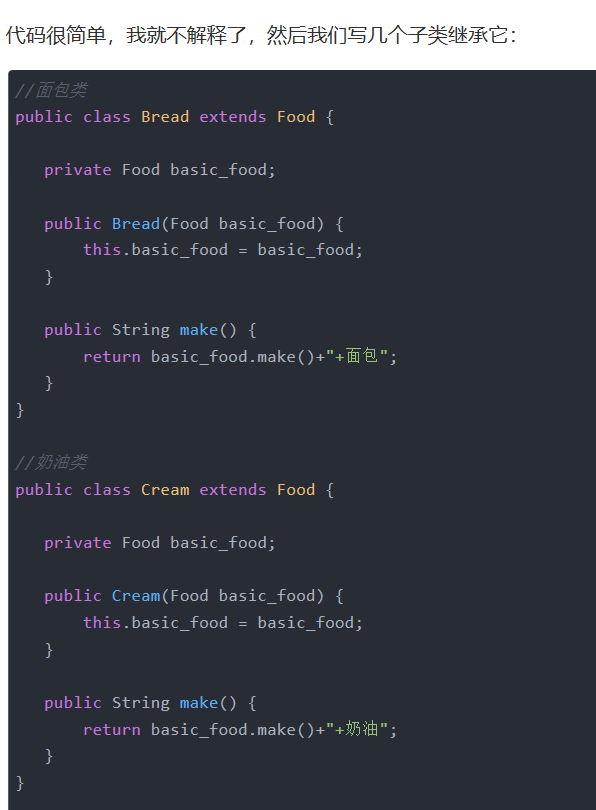
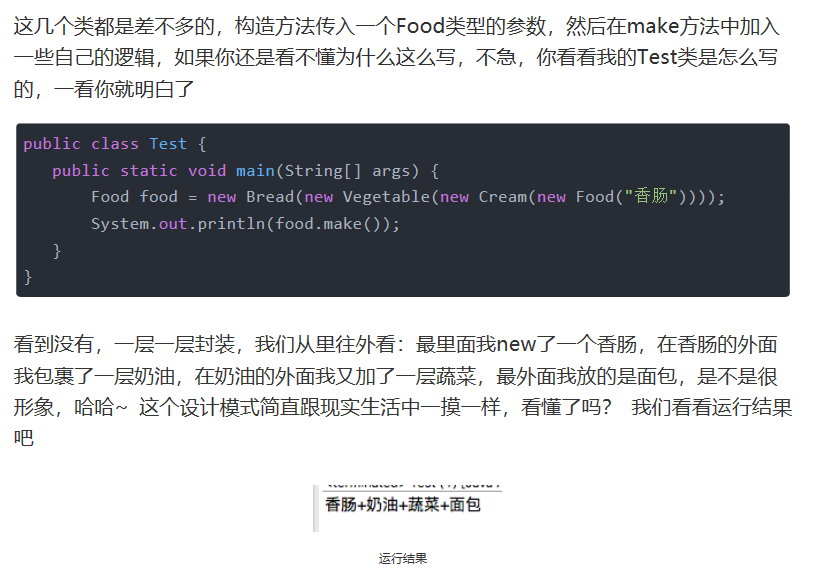
[--------------------------结束](#wtl-24-1)
<span id="wtl-23">开始-------------------------------</span>
==观察者模式==
- 对象间一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
- 可以理解为 mq的订阅和发布
[--------------------------结束](#wtl-23-1)
<span id="wtl-22">开始-------------------------------</span>
==单例模式==
- 简单点说,就是一个应用程序中,某个类的实例对象只有一个,你没有办法去new,因为构造器是被private修饰的,一般通过getInstance()的方法来获取它们的实例。
- getInstance()的返回值是一个对象的引用,并不是一个新的实例,所以不要错误的理解成多个对象。
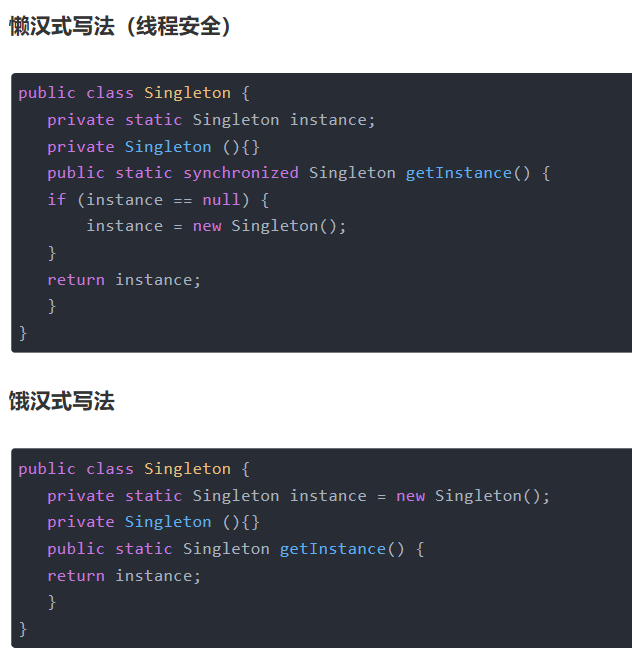


[--------------------------结束](#wtl-22-1)
<span id="wtl-12">开始-------------------------------------</span>
==String 类的常用方法都有那些==
indexOf():返回指定字符的索引。
charAt():返回指定索引处的字符。
replace():字符串替换。
trim():去除字符串两端空白。
split():分割字符串,返回一个分割后的字符串数组。
getBytes():返回字符串的 byte 类型数组。
length():返回字符串长度。
toLowerCase():将字符串转成小写字母。
toUpperCase():将字符串转成大写字符。
substring():截取字符串。
equals():字符串比较。
[--------------------------结束](#wtl-12-1)
<span id="wtl-11">开始-------------------------------------</span>
==String、StringBuffer、StringBuilder的区别==
- String 和 StringBuffer、StringBuilder 的区别在于 String 声明的是不可变的对象,每次操作都会生成新的 String 对象,然后将指针指向新的 String 对象
- 而 StringBuffer、StringBuilder 可以在原有对象的基础上进行操作,所以在经常改变字符串内容的情况下最好不要使用 String。
- StringBuffer 和 StringBuilder 最大的区别在于,StringBuffer 是线程安全的
- 而 StringBuilder 是非线程安全的,但 StringBuilder 的性能却高于 StringBuffer
- 所以在单线程环境下推荐使用 StringBuilder,多线程环境下推荐使用 StringBuffer。
[--------------------------结束](#wtl-11-1)
<span id="wtl-7">开始-------------------------------------</span>
==Spring框架IOC和AOP==
> IOC
- IoC(Inversion of Control)是指容器控制程序对象之间的关系
- 控制权由应用代码中转到了外部容器,控制权的转移是所谓反转
- 对于Spring而言,就是由Spring来控制对象的生命周期和对象之间的关系
- IoC还有另外一个名字——“依赖注入(Dependency Injection)
- 所谓依赖注入,即组件之间的依赖关系由容器在运行期决定,即由容器动态地将某种依赖关系注入到组件之中。
- 依赖注入的思想是通过反射机制实现的
- IoC的优点:降低了组件之间的耦合,降低了业务对象之间替换的复杂性,使之能够灵活的管理对象。
> AOP
- AOP (Aspect Orient Programming),直译过来就是 面向切面编程。AOP 是一种编程思想,是面向对象编程(OOP)的一种补充
- AOP 要达到的效果是,保证开发者不修改源代码的前提下,去为系统中的业务组件添加某种通用功能。
- 
[--------------------------结束](#wtl-7-1)
<span id="wtl-1">开始-------------------------------------</span>
==final==
final 修饰的类叫最终类,该类不能被继承。
final 修饰的方法不能被重写。
final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
- Java中的String类就是一个final类
- 类的private方法会隐式地被指定为final方法。
- 对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
- 很多时候会容易把static和final关键字混淆,static作用于成员变量用来表示只保存一份副本,而final的作用是用来保证变量不可变
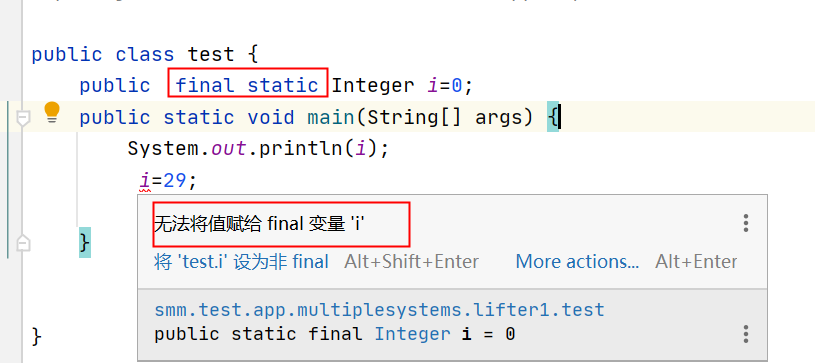

[--------------------------结束](#wtl-1-1)
<span id="wtl-2">开始-------------------------------------</span>
==static==
- “static方法就是没有this的方法。在static方法内部不能调用非静态方法,反过来是可以的。而且可以在没有创建任何对象的前提下,仅仅通过类本身来调用static方法。这实际上正是static方法的主要用途。”
- 方便在没有创建对象的情况下来进行调用(方法/变量)。
- 静态变量被所有的对象所共享,在内存中只有一个副本,它当且仅当在类初次加载时会被初始化。
- static块可以置于类中的任何地方,类中可以有多个static块。在类初次被加载的时候,会按照static块的顺序来执行每个static块,并且只会执行一次。
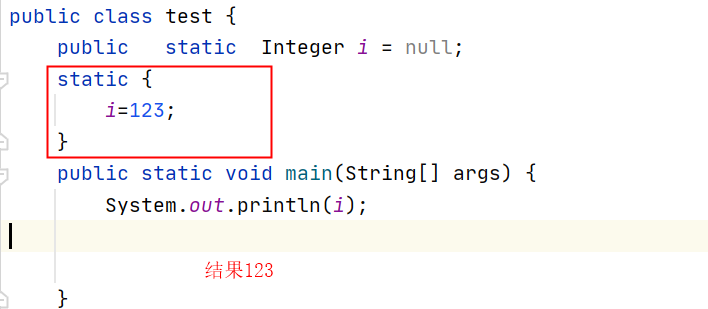
- 因此,很多时候会将一些只需要进行一次的初始化操作都放在static代码块中进行。
[--------------------------结束](#wtl-2-1)
<span id="wtl-3">开始-------------------------------------</span>
==线程的创建方式有几种==

- 继承Thread类
- 实现Runnable接口、
- 实现Callable接口通过FutureTask包装器来创建Thread线程、
- 使用ExecutorService、Callable、Future实现有返回结果的多线程。
- 其中前两种方式线程执行完后都没有返回值,后两种是带返回值的。
[--------------------------结束](#wtl-3-1)
<span id="wtl-4">开始-------------------------------------</span>
==AQS 模板模式==
AQS原理
AQS:AbstractQuenedSynchronizer抽象的队列式同步器。是除了java自带的synchronized关键字之外的锁机制。
AQS的核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并将共享资源设置为锁定状态,如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列,虚拟的双向队列即不存在队列实例,仅存在节点之间的关联关系。
AQS是将每一条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node),来实现锁的分配。
用大白话来说,AQS就是基于CLH队列,用volatile修饰共享变量state,线程通过CAS去改变状态符,成功则获取锁成功,失败则进入等待队列,等待被唤醒。
**注意:AQS是自旋锁:**在等待唤醒的时候,经常会使用自旋(while(!cas()))的方式,不停地尝试获取锁,直到被其他线程获取成功
实现了AQS的锁有:自旋锁、互斥锁、读锁写锁、条件产量、信号量、栅栏都是AQS的衍生物
AQS实现的具体方式如下:
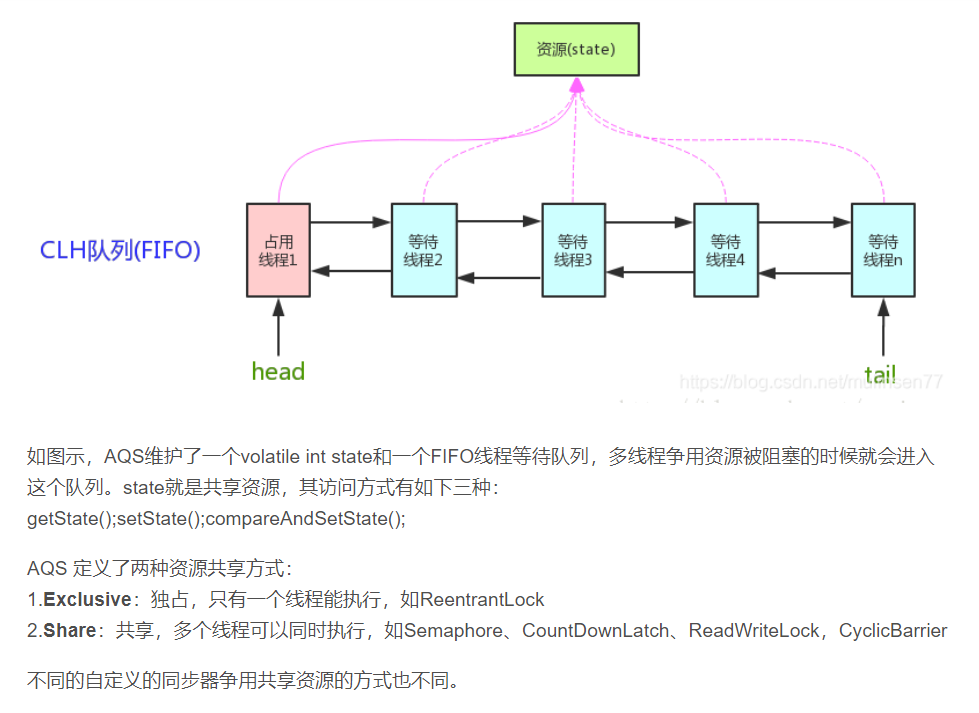
[--------------------------结束](#wtl-4-1)
<span id="wtl-5">开始-------------------------------------</span>
==spring @autowired @resource注解==
- @Autowired注解是按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它required属性为false。@Resource注解和@Autowired一样,也可以标注在字段或属性的setter方法上,但它默认按名称装配。名称可以通过
- @Resource的name属性指定,如果没有指定name属性,当注解标注在字段上,即默认取字段的名称作为bean名称寻找依赖对象,当注解标注在属性的setter方法上,即默认取属性名作为bean名称寻找依赖对象。
- @Resources按名字,是JDK的,@Autowired按类型,是Spring的。
[--------------------------结束](#wtl-5-1)
<span id="wtl-6">开始-------------------------------------</span>
==Spring-bean的循环依赖以及解决方式==
- 什么是循环依赖?
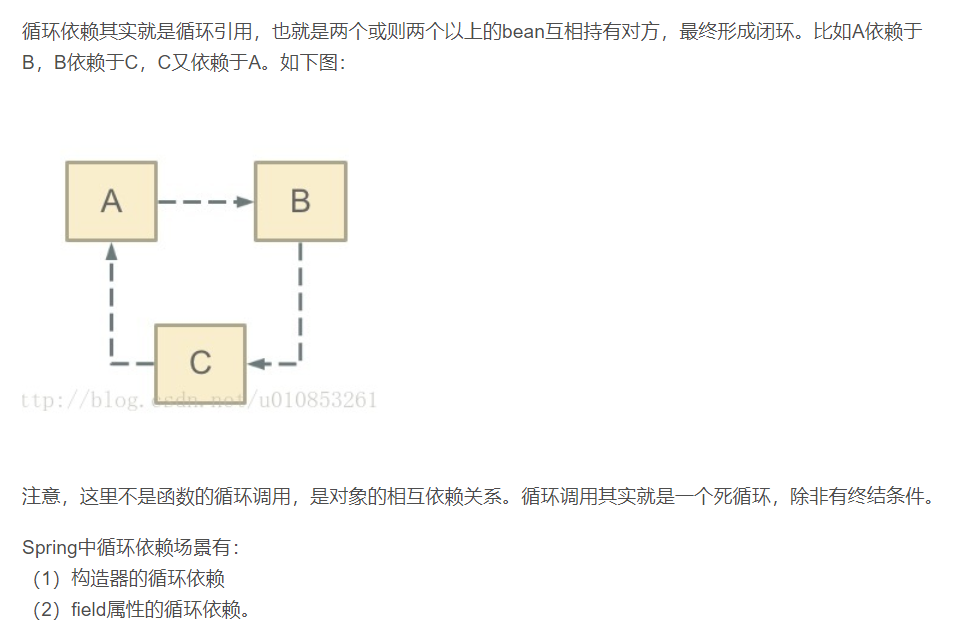
- Spring 是如何解决的
其实很简单、在 Spring 获取单例流程(一) 中我们曾提及过三级缓存
> 这三级缓存分别指:
singletonFactories : 单例对象工厂的cache
earlySingletonObjects :提前暴光的单例对象的Cache
singletonObjects:单例对象的cache
[--------------------------结束](#wtl-6-1)
<span id="wtl-21">开始-------------------------------------</span>
==list -set -map 及其实现类==
- List 有顺序,可以有重复对象
- LinkedList 基于链表实现,链表内存是散列的,增删快,查找慢;
- ArrayList 基于数组实现,非线程安全,效率高,增删慢,查找快;
- Vector 基于数组实现,线程安全,效率低,增删慢,查找慢;
- Set 集合中的对象无序,并且没有重复对象
- HashSet 底层是由 Hash Map 实现,不允许集合中有重复的值,使用该方式时需要重写 equals()和 hash Code()方法;
- LinkedHashSet 继承于 HashSet,同时又基于 LinkedHashMap 来进行实现,底层使用的是 LinkedHashMap
- Map 中的每一个元素包含一个键和一个值,成对出现,键对象不可以重复,值对象可以重复;
- HashMap 基于 hash 表的 Map 接口实现,非线程安全,高效,支持 null 值和 null
- HashTable 线程安全,低效,不支持 null 值和 null 键;
- LinkedHashMap 是 HashMap 的一个子类,保存了记录的插入顺序;
- TreeMap,能够把它保存的记录根据键排序,默认是键值的升序排序 {SortMap 接口 }
[--------------------------结束](#wtl-21-1)
<span id="wtl-04011">开始-------------------------------------</span>
==Java中有几种类型的流==
1.字节流和字符流
2.字节流继承inputStream和OutputStream
3.字符流继承自InputSteamReader和OutputStreamWriter
==流:字节流和字符流哪个好?==
- 大多数情况下使用字节流会更好,因为字节流是字符流的包装,而大多数时候 IO 操作都是直接操作磁盘文件,所以这些流在传输时都是以字节的方式进行的(图片,视频,音频等都是按字节存储的)
- 如果对于操作需要通过 IO 在内存中频繁处理字符串的情况使用字符流会好些,因为字符流具备缓冲区,提高了性能
[--------------------------结束](#wtl-12-1)
<span id="wtl-04013">开始-------------------------------------</span>
==三次握手的概念==
- 第一次握手:建立连接时,客户端发送syn 包(syn=j)到服务器,并进入SYN_SENT 状态,
等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
- 第二次握手:服务器收到syn 包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN
包(syn=k),即SYN+ACK 包,此时服务器进入SYN_RECV 状态;
- 第三次握手:客户端收到服务器的SYN+ACK 包,向服务器发送确认包ACK(ack=k+1),此包
发送完毕,客户端和服务器进入ESTABLISHED(TCP 连接成功)状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据
---
总结
- 建立连接时,发送状态1,进入等待
- 服务器收到1,同时自己也发送一个状态2
- 客户端收到服务器的状态2,向服务器发送确认状态3
- 发送完毕,客户端和服务器(TCP 连接成功)状态,完成三次握手。客户端与服务器开始传送数据
[--------------------------结束](#wtl-12-1)
<span id="wtl-04014">开始-------------------------------------</span>
==JSP九大内置对象==
- pageContext:表示页面的上下文的对象封存了其它的内置对象,封存了当前页面的运行信息
- request:封装当前请求的数据,由tomact创建,一次请求对应一个request对象
- session:用来封装同一个用户的不同请求的共享数据,一次会话对应一个session对象
- application:相当于ServletContext对象,一个web项目只有一个对象,存储着所有用户的共享数据,从服务器启动到服务器结束
- response:响应对象,用来响应请求数据,将处理结果返回个浏览器,可以进行重定向
- page:代表当前 jsp对象,跟java中的this指针类似
- exception:异常对象,存储当前运行的异常信息,必须在- page指令中添加属性isErrorPage=true
- config:相当于Serlverconfig对象,用来获取web.xml中配置的数据,完成servlet的初始化操作
- out:响应对象,jsp内部使用,带有缓存区的响应对象,效率要高于response
[--------------------------结束](#wtl-12-1)
<span id="wtl-04025">开始-------------------------------------</span>
==索引的优点-缺点==
- 优点
- 可以快速读取数据提高查询速度;
- 可以保证数据记录的唯一性;
- 可以加速表与表的连接
- 可以显著的减少查询中分组和排序的时间。
- 缺点
- 创建索引和维护索引需要时间,而且数据量越大时间越长
- 创建索引需要占据磁盘的空间,如果有大量的索引,可能比数据文件还要大。
- 当对表中的数据进行增加,修改,删除的时候,索引也要同时进行维护,降低了数据的维护速度
[--------------------------结束](#wtl-30-1)
<span id="wtl-04025">开始-------------------------------------</span>
==SQL语句优化==
- Where子句中:where表之间的连接必须写在其他Where条件之前,那些可以过滤掉最大数量记录的条件必须写在Where子句的末尾.HAVING最后。
- 避免在索引列上使用计算
- 避免在索引列上使用IS NULL和IS NOT NULL
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
- 应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
- 把*改为前端所需要的字段名
- 模糊查询比如‘%xxx%’,因此该查询必然走全表扫描,除非必要,否则不要在关键词前加%。
- 用EXISTS替代IN、用NOT EXISTS替代NOT IN。
[--------------------------结束](#wtl-30-1)
<span id="wtl-04027">开始-------------------------------------</span>
==SpringMVC请求处理流程==
(1)用户发送请求至前端控制器DispatcherServlet;
(2) DispatcherServlet收到请求后,调用HandlerMapping处理器映射器,请求获取Handler;
(3)处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet;
(4)DispatcherServlet 调用 HandlerAdapter处理器适配器;
(5)HandlerAdapter 经过适配调用 具体处理器(Handler,也叫后端控制器);
(6)Handler执行完成返回ModelAndView;
(7)HandlerAdapter将Handler执行结果ModelAndView返回给DispatcherServlet;
(8)DispatcherServlet将ModelAndView传给ViewResolver视图解析器进行解析;
(9)ViewResolver解析后返回具体View;
(10)DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)
(11)DispatcherServlet响应用户。
> 总结 :
- 用户向服务器发送请求
- DispathcerServlet接收请求找到具体的controller并执行
- controller执行完成返回ModelAndView
- 前端控制器调用视图解析器解析ModelAndView返回具体的view
- 渲染页面,响应给用户。
[--------------------------结束](#wtl-5-1)
<span id="wtl-04028">开始-------------------------------------</span>
==Spring什么情况下事务会失效==
- 事务只能应用于 public 方法。
- 当绕过代理对象, 直接调用添加事务管理的方法时, 事务管理将无法生效。在Service中添加@Transactional注解,好处是减少代码。
- 当在方法中使用try捕捉异常的时候
[--------------------------结束](#wtl-5-1)
<span id="wtl-040210">开始-------------------------------------</span>
==SpringBoot有哪些优点==
1、快速构建项目。
2、对主流开发框��的无配置集成。
3、项目可独立运行,无须外部依赖Servlet容器。
4、提供运行时的应用监控。
5、极大的提高了开发、部署效率。
6、与微服务的天然集成
[--------------------------结束](#wtl-5-1)
<span id="wtl-040211">开始-------------------------------------</span>
==SpringBoot的自动配置原理==
- Spring Boot的启动类上有一个@SpringBootApplication注解@SpringBootApplication是一个复合注解或派生注解,在@SpringBootApplication中有一个注解@EnableAutoConfiguration,开启自动配置。通过Import注解导入AutoConfigurationImportSelector。在这个类中加载/META-INF/spring.factories文件的信息,然后筛选出以EnableAutoConfiguration为key的数据,加载到IOC容器中,实现自动配置功能。
https://blog.csdn.net/Zzze0101/article/details/98625755
[--------------------------结束](#wtl-5-1)
<span id="wtl-04031">开始-------------------------------------</span>
==Spring框架中都用了哪些设计模式==
- 工厂设计模式 : Spring使用工厂模式通过 BeanFactory、ApplicationContext 创建 bean 对象。
- 代理设计模式 : Spring AOP 功能的实现。
- 单例设计模式 : Spring 中的 Bean 默认都是单例的。
- 模板方法模式 : Spring 中 jdbcTemplate、hibernateTemplate 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。
包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
- 观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
- 适配器模式 :Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配Controller。
[--------------------------结束](#wtl-5-1)
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1