🍐 Dockerfile编写
# Dockerfile编写
使用容器的方式部署有诸多好处,不再赘述了
## 常用torchserve镜像及包版本
docker 拉取镜像:
`docker pull pytorch/torchserve:0.4.2-gpu`
镜像比较老旧了,python是3.6.9版本的
```language
model-server@5349733dfdld:~$ pip list | grep numpy
numpy 1.19.5
WARNING: You are using pip version 21.2.1: however, version 21.3.1 is available.l You should consider upgrading via the '/usr/bin/python3 -m pip install --upgrade pip' command.
model-server@5349733dfdld:~$ pip list | grep torch
torch 1.9.0
torch-model-archiver 0.4.2
torch-workflow-archiver 0.1.2
torchaudio 0.9.0
torchserve 0.4.2
torchtext 0.10.0
torchvision 0.10.0
```
除了上面较为常见的库,其余库都没有了
公司里使用的镜像可能是经过改造的,对应包的变化,最好沟通一下。
Docker容器里的CUDA版本和显卡驱动版本不由Dockfile控制,如果项目运行对CUDA版本有要求,需使用安装对应版本CUDA的宿主机,容器应运行在此宿主机下。
## torchserve的目录结构
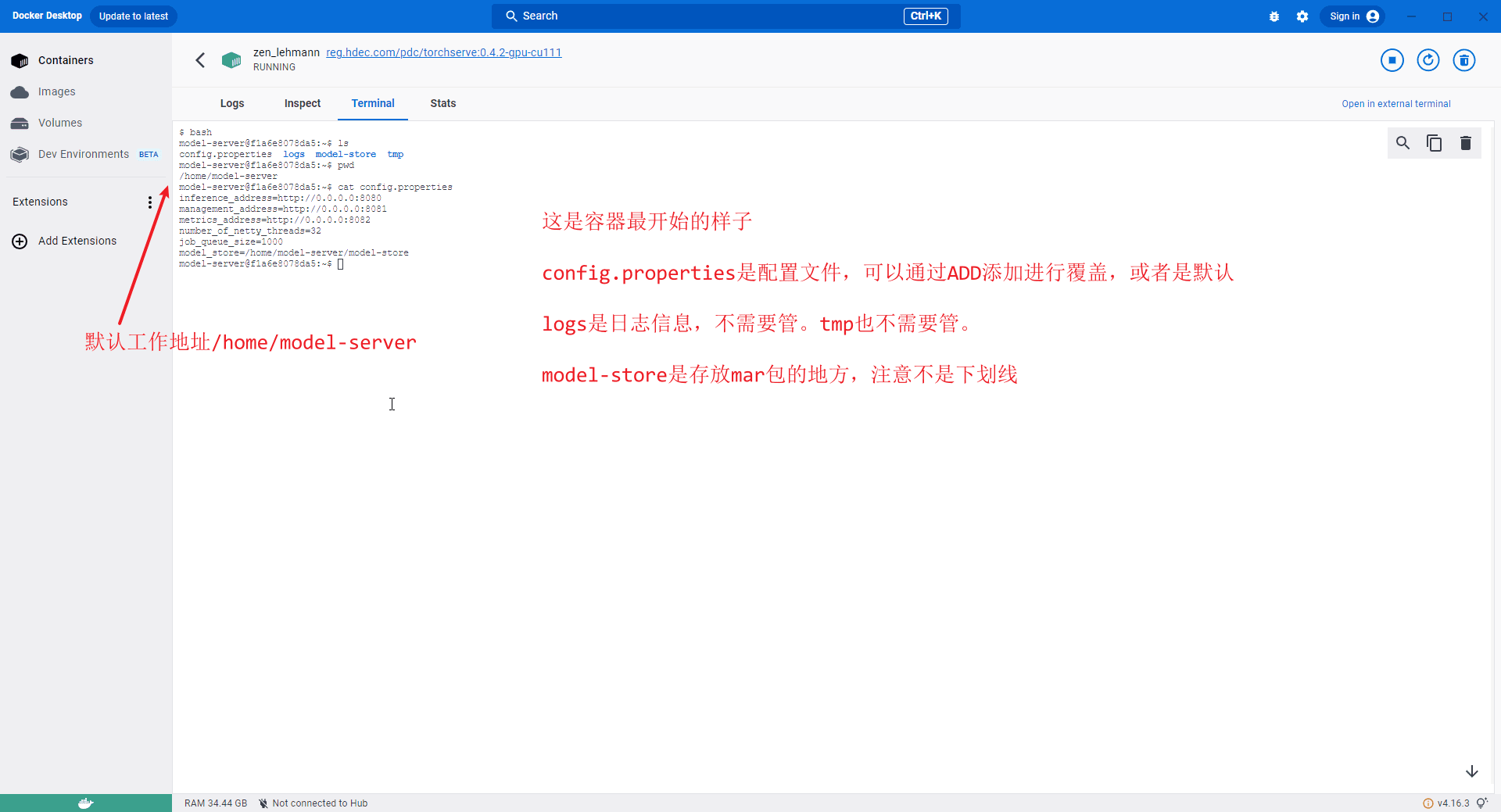
>i 如果没有必要,不要使用root权限,也不要更改工作地址。
>i /home/model-server是默认工作地址,/home/model-server/model-store都是分隔符进行连接的,不是下划线,server是带字母r的,torchserve是不带字母r的。
## Dockfile例子
```Dockerfile
FROM reg.hdec.com/pdc/torchserve:0.4.2-gpu-cu111
WORKDIR /home/model-server
ENV LANG=C.UTF-8
# 添加所有的文件到/home/model-server下面
# 原则上和容器构建无关的文件不允许进入
# 为了方便考虑,允许添加体积较小的文本文件进入,比如build.sh
# 大于50MB的文件,比如数据,模型文件需使用.dockerignore文件排除
ADD . /home/model-server
# 更新pip的版本
RUN pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
...
EXPOSE 8080 8081 8082 7070 7071
# 保险起见,写多重命令的时候可以使用"'command1' && 'command2' &&..."的格式书写,当然有的情况"command1 && command2 && ..."也是可以的
# 此例子中就是不可以的,可以在命令行中运行bash -c python xxx.py, 结果是不会执行xxx.py文件,而是进入交互式界面。
# 后面的torch-model-archiver 和 torchserve就没事。
# fmsClient.py文件用于传输模型文件,其中最好不要含有中文字符,注释除外
CMD ["/bin/bash","-c","'python fmsClient.py' && torch-model-archiver --model-name tsm_action --version 1.0 --serialized-file tsm_action.pth --export-path model-store --extra-files label.txt,tsm_r50_video_1x1x8_50e_kinetics400_rgb.py,tsm_r50.py,sgd_tsm_50e.py,default_runtime.py --handler handler.py -f && torchserve --start --model-store model-store --models tsm_action=tsm_action.mar"]
```
## fmsClient.py
Dockerfile的最后一行出现了fmsClient.py
这是为了防止容器体积过大所采取的措施
fmsClinet.py是一个模型文件下载器,模型文件由模型训练者上传至[文件服务管理系统](http://fms.ecidi.com/index)
fmsClinet.py在使用时需要设置以下三个变量:
1. documentId='xxx' 文件ID
2. version='0001' 文件版本
3. folder='xxx' 下载至指定文件夹
```python
import os
import json
import requests
from urllib.request import urlretrieve
# 链接文件服务下载 模型文件 tar
# 输入 documentId, path
# 输出 下载的文件 xxx.tar
"""
判断文件是否存在,存在无效果,不存在则生成文件夹
path:文件的绝对路径,通过获取当前文件的绝对路径,再将文件夹文件拼接起来
"""
def is_exists_dir_create(path):
if not os.path.exists(path):
os.makedirs(path)
def get_model(documentId, version=None, folder=None):
"""
input:
documentId:2c91808279e9657c017b51e236350131
version:版本 '0001','0002',...
folder:创建的文件夹名(当前路径下)
return: downloadUrl
且下载至folder文件夹
"""
# 创建文件夹(若不存在时)
is_exists_dir_create(folder)
# 请求头
header = {
'Authorization': 'Bearer eyJhbGciOiJIUzI1NiJ9.eyJqdGkiOiIyYzkxODA4Mjc2NDA0ZmRkMDE3OGVkZGI4OWQyMDFiMiIsInN1Y'
'iI6ImhkZWNhaSIsImlzcyI6IkVDSURJIiwiaWF0IjoxNjE4ODk4MzE4LCJleHAiOjE3NDUxMjczNzN9.OlTxOxXGG7'
'2ORt9pUBK6QDv8g3Iw4WL_8DuJQPqg760'
}
# 获取文件信息和版本
# 设置pagesize=1000
# 默认url为当前版本的
url = 'http://fms.hdec.com/service/api/document/' + documentId + '/?page=1&pageSize=1000&bucketName='
r = requests.get(url=url, headers=header)
all_data = json.loads(r.text)
# 获取文件名
name = all_data.get("data").get("name")
# 默认下载地址
url_download = 'http://fms.hdec.com/service/api/document/' + documentId + '/objecturl'
# 如果指定历史版本,即:
if (version is not None) and (int(version) > 0):
num = int(version)
url = 'http://fms.hdec.com/service/api/document/' + documentId + '/history?page=1&pageSize=1000&bucketName='
r = requests.get(url=url, headers=header)
all_data = json.loads(r.text)
content = all_data.get("data").get("content")
# total 代表存在的历史版本总数
total = all_data.get("data").get("totalElements")
if total == 0:
print("No historical version, download the current version.")
elif int(version) > total:
print("This version does not exist in the history, download the current version.")
else:
# 通过id获取真实的下载地址
Id = content[num - 1].get("id")
# 获取文件名
name = content[num - 1].get("name")
url_download = 'http://fms.hdec.com/service/api/document/history/' + Id + '/objecturl'
# 获取真实的下载地址
url = url_download
data = requests.get(url, headers=header)
response = json.loads(data.text)
url_true = response.get("data")
img_path = folder + '/' + name
# 若不需要下载,则注释以下代码
# 覆盖原重名文件:
# urlretrieve(url_true, img_path)
# 忽略重名文件,不下载:
if not os.path.exists(img_path):
urlretrieve(url_true, img_path)
return url_true
if __name__ == '__main__':
try:
get_model(documentId='xxx', version='0001', folder='/home/model-server')
except Exception as e:
print("An error has occurred")
print(e)
```
## config.properties编写
>i 一般情况下,使用容器部署不需要填写,本地部署填写一下比较保险
torchserve使用`--ts-config`进行config.properties文件的指定。
```
inference_address=http://0.0.0.0:8080
management_address=http://0.0.0.0:8081
metrics_address=http://0.0.0.0:8082
number_of_netty_threads=32
job_queue_size=1000
model_store=/home/model-server/model-store
#####上方的几行默认写在了镜像里#####
workflow_store=/home/model-server/wf-store
load_models=all
install_py_dep_per_model=false
# 单位是字节,代表输入数据的最大容量
# 如果传入视频,建议设置大一些,不然拒绝推理
max_request_size=15535000
cors_allowed_origin=*
cors_allowed_methods=GET,POST,PUT,OPTIONS
default_workers_per_model=1
```