kubernetes简要
### 首先,Kubernetes 项目要解决的问题是什么?
编排?调度?容器云?还是集群管理?
实际上,这个问题到目前为止都没有固定的答案。因为在不同的发展阶段,Kubernetes 需要着重解决的问题是不同的。但是,对于大多数用户来说,他们希望 Kubernetes 项目带来的体验是确定的:现在我有了应用的容器镜像,请帮我在一个给定的集群上把这个应用运行起来。更进一步地说,我还希望 Kubernetes 能给我提供路由网关、水平扩展、监控、备份、灾难恢复等一系列运维能力。
等一下,这些功能听起来好像有些耳熟?这不就是经典 PaaS(比如,Cloud Foundry)项目的能力吗?而且,有了 Docker 之后,我根本不需要什么 Kubernetes、PaaS,只要使用 Docker 公司的 Compose+Swarm 项目,就完全可以很方便地 DIY 出这些功能了!所以说,如果 Kubernetes 项目只是停留在拉取用户镜像、运行容器,以及提供常见的运维功能的话,那么别说跟“原生”的 Docker Swarm 项目竞争了,哪怕跟经典的 PaaS 项目相比也难有什么优势可言。
而实际上,在定义核心功能的过程中,Kubernetes 项目正是依托着 Borg 项目的理论优势,才在短短几个月内迅速站稳了脚跟,进而确定了一个如下图所示的全局架构:
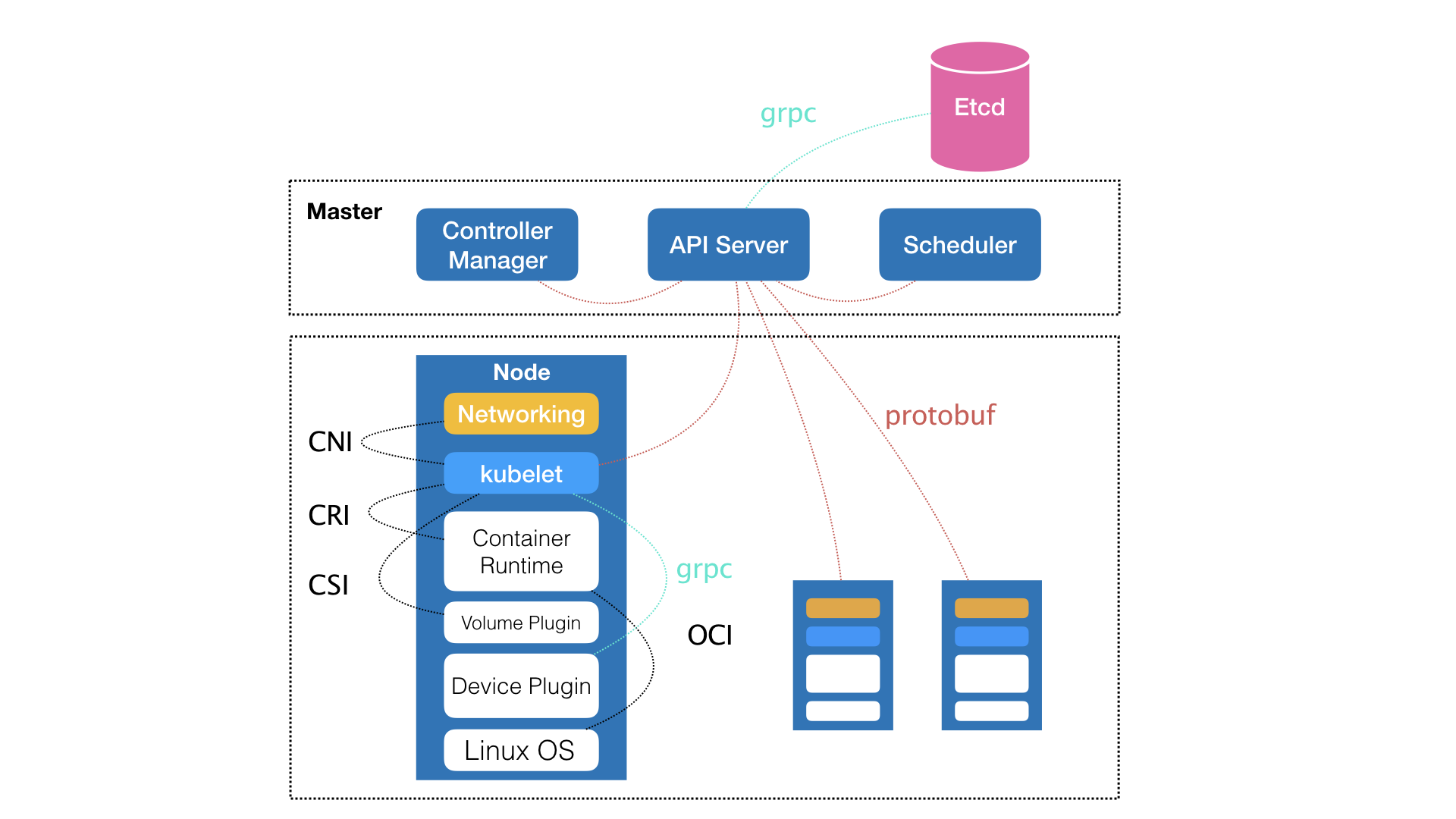
我们可以看到,Kubernetes 项目的架构,跟它的原型项目 Borg 非常类似,都由 Master 和 Node 两种节点组成,而这两种角色分别对应着控制节点和计算节点。
其中,控制节点,即 Master 节点,由三个紧密协作的独立组件组合而成,它们分别是负责 API 服务的 kube-apiserver、负责调度的 kube-scheduler,以及负责容器编排的 kube-controller-manager。整个集群的持久化数据,则由 kube-apiserver 处理后保存在 Etcd 中。而计算节点上最核心的部分,则是一个叫作 kubelet 的组件。在 Kubernetes 项目中,kubelet 主要负责同容器运行时(比如 Docker 项目)打交道。而这个交互所依赖的,是一个称作 CRI(Container Runtime Interface)的远程调用接口,这个接口定义了容器运行时的各项核心操作,比如:启动一个容器需要的所有参数。
这也是为何,Kubernetes 项目并不关心你部署的是什么容器运行时、使用的什么技术实现,只要你的这个容器运行时能够运行标准的容器镜像,它就可以通过实现 CRI 接入到 Kubernetes 项目当中。而具体的容器运行时,比如 Docker 项目,则一般通过 OCI 这个容器运行时规范同底层的 Linux 操作系统进行交互,即:把 CRI 请求翻译成对 Linux 操作系统的调用(操作 Linux Namespace 和 Cgroups 等)。
此外,kubelet 还通过 gRPC 协议同一个叫作 Device Plugin 的插件进行交互。这个插件,是 Kubernetes 项目用来管理 GPU 等宿主机物理设备的主要组件,也是基于 Kubernetes 项目进行机器学习训练、高性能作业支持等工作必须关注的功能。而 kubelet 的另一个重要功能,则是调用网络插件和存储插件为容器配置网络和持久化存储。这两个插件与 kubelet 进行交互的接口,分别是 CNI(Container Networking Interface)和 CSI(Container Storage Interface)。实际上,kubelet 这个奇怪的名字,来自于 Borg 项目里的同源组件 Borglet。不过,如果你浏览过 Borg 论文的话,就会发现,这个命名方式可能是 kubelet 组件与 Borglet 组件的唯一相似之处。因为 Borg 项目,并不支持我们这里所讲的容器技术,而只是简单地使用了 Linux Cgroups 对进程进行限制。这就意味着,像 Docker 这样的“容器镜像”在 Borg 中是不存在的,Borglet 组件也自然不需要像 kubelet 这样考虑如何同 Docker 进行交互、如何对容器镜像进行管理的问题,也不需要支持 CRI、CNI、CSI 等诸多容器技术接口。
可以说,kubelet 完全就是为了实现 Kubernetes 项目对容器的管理能力而重新实现的一个组件,与 Borg 之间并没有直接的传承关系。备注:虽然不使用 Docker,但 Google 内部确实在使用一个包管理工具,名叫 Midas Package Manager (MPM),其实它可以部分取代 Docker 镜像的角色。那么,Borg 对于 Kubernetes 项目的指导作用又体现在哪里呢?答案是,Master 节点。虽然在 Master 节点的实现细节上 Borg 项目与 Kubernetes 项目不尽相同,但它们的出发点却高度一致,即:如何编排、管理、调度用户提交的作业?所以,Borg 项目完全可以把 Docker 镜像看作一种新的应用打包方式。这样,Borg 团队过去在大规模作业管理与编排上的经验就可以直接“套”在 Kubernetes 项目上了。这些经验最主要的表现就是,从一开始,Kubernetes 项目就没有像同时期的各种“容器云”项目那样,把 Docker 作为整个架构的核心,而仅仅把它作为最底层的一个容器运行时实现。
而在容器技术普及之前,传统虚拟机环境对这种关系的处理方法都是比较“粗粒度”的。你会经常发现很多功能并不相关的应用被一股脑儿地部署在同一台虚拟机中,只是因为它们之间偶尔会互相发起几个 HTTP 请求。更常见的情况则是,一个应用被部署在虚拟机里之后,你还得手动维护很多跟它协作的守护进程(Daemon),用来处理它的日志搜集、灾难恢复、数据备份等辅助工作。
但容器技术出现以后,你就不难发现,在“功能单位”的划分上,容器有着独一无二的“细粒度”优势:毕竟容器的本质,只是一个进程而已。也就是说,只要你愿意,那些原先拥挤在同一个虚拟机里的各个应用、组件、守护进程,都可以被分别做成镜像,然后运行在一个个专属的容器中。它们之间互不干涉,拥有各自的资源配额,可以被调度在整个集群里的任何一台机器上。而这,正是一个 PaaS 系统最理想的工作状态,也是所谓“微服务”思想得以落地的先决条件。
当然,如果只做到“封装微服务、调度单容器”这一层次,Docker Swarm 项目就已经绰绰有余了。如果再加上 Compose 项目,你甚至还具备了处理一些简单依赖关系的能力,比如:一个“Web 容器”和它要访问的数据库“DB 容器”。在 Compose 项目中,你可以为这样的两个容器定义一个“link”,而 Docker 项目则会负责维护这个“link”关系,其具体做法是:Docker 会在 Web 容器中,将 DB 容器的 IP 地址、端口等信息以环境变量的方式注入进去,供应用进程使用,比如:
```
DB_NAME=/web/db
DB_PORT=tcp://172.17.0.5:5432
DB_PORT_5432_TCP=tcp://172.17.0.5:5432
DB_PORT_5432_TCP_PROTO=tcp
DB_PORT_5432_TCP_PORT=5432
DB_PORT_5432_TCP_ADDR=172.17.0.5
```
而当 DB 容器发生变化时(比如,镜像更新,被迁移到其他宿主机上等等),这些环境变量的值会由 Docker 项目自动更新。这就是平台项目自动地处理容器间关系的典型例子。可是,如果我们现在的需求是,要求这个项目能够处理前面提到的所有类型的关系,甚至还要能够支持未来可能出现的更多种类的关系呢?
这时,“link”这种单独针对一种案例设计的解决方案就太过简单了。如果你做过架构方面的工作,就会深有感触:一旦要追求项目的普适性,那就一定要从顶层开始做好设计。所以,Kubernetes 项目最主要的设计思想是,从更宏观的角度,以统一的方式来定义任务之间的各种关系,并且为将来支持更多种类的关系留有余地。
比如,Kubernetes 项目对容器间的“访问”进行了分类,首先总结出了一类非常常见的“紧密交互”的关系,即:这些应用之间需要非常频繁的交互和访问;又或者,它们会直接通过本地文件进行信息交换。在常规环境下,这些应用往往会被直接部署在同一台机器上,通过 Localhost 通信,通过本地磁盘目录交换文件。
而在 Kubernetes 项目中,这些容器则会被划分为一个“Pod”,Pod 里的容器共享同一个 Network Namespace、同一组数据卷,从而达到高效率交换信息的目的。Pod 是 Kubernetes 项目中最基础的一个对象,源自于 Google Borg 论文中一个名叫 Alloc 的设计。
而对于另外一种更为常见的需求,比如 Web 应用与数据库之间的访问关系,Kubernetes 项目则提供了一种叫作“Service”的服务。像这样的两个应用,往往故意不部署在同一台机器上,这样即使 Web 应用所在的机器宕机了,数据库也完全不受影响。可是,我们知道,对于一个容器来说,它的 IP 地址等信息不是固定的,那么 Web 应用又怎么找到数据库容器的 Pod 呢?所以,Kubernetes 项目的做法是给 Pod 绑定一个 Service 服务,而 Service 服务声明的 IP 地址等信息是“终生不变”的。这个 Service 服务的主要作用,就是作为 Pod 的代理入口(Portal),从而代替 Pod 对外暴露一个固定的网络地址。这样,对于 Web 应用的 Pod 来说,它需要关心的就是数据库 Pod 的 Servic信息。不难想象,Service 后端真正代理的 Pod 的 IP 地址、端口等信息的自动更新、维护,则是 Kubernetes 项目的职责。