kubectl&helm
# helm
## helm3 下载
```bash
wget https://get.helm.sh/helm-v3.5.2-linux-amd64.tar.gz
tar -zxf helm-v3.5.2-linux-amd64.tar.gz
cp linux-amd64/helm /usr/bin/helm3
helm3 version
```
# kubectl
## 下载
```
https://kubernetes.io/zh-cn/docs/tasks/tools/install-kubectl-windows/#install-kubectl-binary-with-curl-on-windows
```
` --kubeconfig ./config `
配置命令补全
```
yum install -y bash-completion
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> ~/.bashrc
```
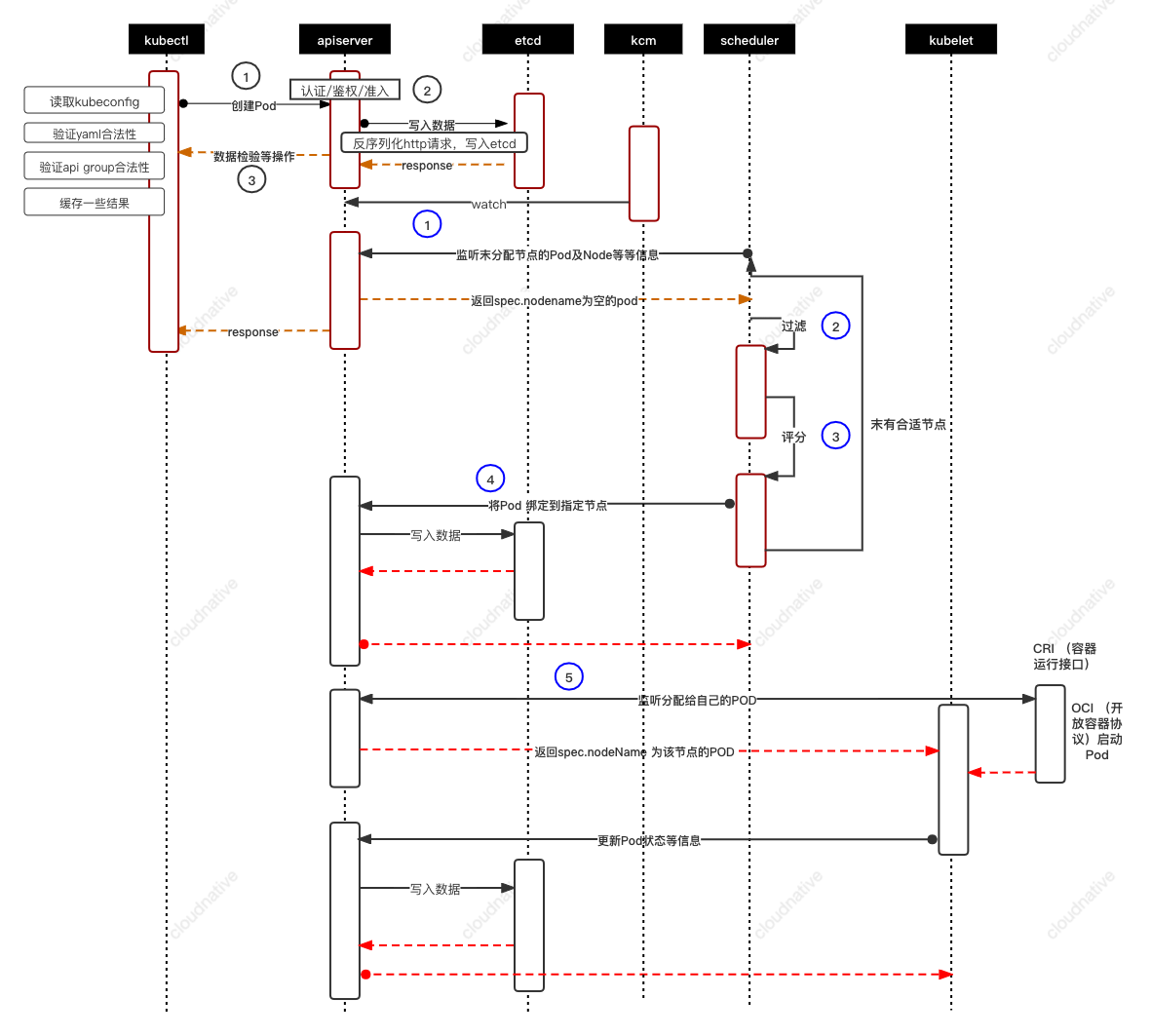
## kubectl create -f 背后发生了什么
kubectl run pod
kubectl create -f deployment.yaml
### 1.kubectl
读kubeconfig
执行客户端验证,以确保非法的请求不被送到apiserver,比如请求了一个不存在的kind,kubectl就会报错。(也就是低版本kubectl连高版本的kubernetes apiserver会有一些兼容性问题)
验证yaml文件
缓存 /root/.kube/cache
## 2.kube-apiserver
认证,鉴权,准入
### 3.etcd
kube-apiserver 将反序列化 HTTP 请求,构造运行时对象(runtime object)并将它们持久化到 etcd。
资源会通过 storage provider 存储到 etcd 中。默认情况下,保持到 etcd 的键的格式为 <namespace>/<name>,
资源创建过程中出现的任何错误都会被捕获,最后 storage provider 会执行 get 调用来确认该资源是否被成功创建。如果需要额外的清理工作 (finalization),就会调用后期创建的处理器和装饰器,最后,构造 HTTP 响应并返回给客户端。
### 4.kube-controller-manager
KCM里的deployment controller 通过apiserver watch到里多了一个deployment,这个controller就开始干活了
控制rs,pod等等,
### 5.Scheduler
当所有的 Controller 正常运行后,etcd 中就会保存一个 Deployment、一个 ReplicaSet 和 一个 Pod, 并且可以通过 kube-apiserver 查看到。调度器这时候开始工作
### 6.kubelet
当调度器完成调度,kubelet才开始做真正的事情,启动容器,挂载volume等等。
## 操作
使用 kubectl 动态修改 env
```
kubectl set env deployment/name env_name=env_value
```
重启deploy
```
kubectl rollout restart deployment -n namespace deploy-name
```
示例
将名为foo中的pod副本数设置为3。
```
kubectl scale --replicas=3 rs/foo
```
将由“foo.yaml”配置文件中指定的资源对象和名称标识的Pod资源副本设为3。
```
kubectl scale --replicas=3 -f foo.yaml
```
如果当前副本数为2,则将其扩展至3。
```
kubectl scale --current-replicas=2 --replicas=3 deployment/mysql
```
设置多个RC中Pod副本数量。
```
kubectl scale --replicas=5 rc/foo rc/bar rc/baz
```