Redis 集群搭建-服务器相关
## 1.个数
### **++6++**
>各个Redis服务器之间的链接采用的是Ping-Pong机制使每个服务器间相互通信,检测一个节点是否挂掉采用的是节点间的相互检测(相互投票)。当一个节点被该集群中超过半数的节点检测出有问题,即认为该节点挂掉。所以想要投票过半。节点数至少为3个。又因为一般情况下,为了保证服务器的数据安全,都会采用一主一备(至少一备)的方式,所以一个最小单元的集群,一共需要6台服务器。
>当然两个节点也可以搭建集群,但是这样的高可用型不强,且不能采用投票机制检查节点是否正常工作。这时候可以借助另外的参考节点,可以和测试ping通,但不可以和对方通,说明对方节点有问题,或节点本身有问题,还有就是可以通过仲裁设备,如仲裁磁盘,每个节点间隔一定时间不停的往磁盘写数据,若监控到对方不再写入的时候,可能对方节点出故障。
---
## 2.内存
++**占用率阈值:50%, 75%**++
极限情况:留出一倍内存,比如你的Redis数据占用了8G内存,那么你需要预留出8G空闲内存,也就是内存需求是16G,内存占用了低于50%是最安全的。
普通情况:正常情况下,在序列化周期内,不会更改所有数据,只会有部分数据更改,那么预留出可能产生的更改部分的空间,就行。如果实在要说一个数据的话,内存占用率低于75%都是安全的。
>s到底需要多大内存,还需要看实际业务场景,业务量来定。
就当前我们的Redis使用情况来看,截止到目前为止(2021-07-27),内存使用还不到100M.
>iPS:这里我认为任何服务器的内存占用率都不要超过这个值。75%。因为你不知道什么时候会产生波动,若占用率过高,可能当偶尔产生大的波动时,一下就给服务干死了。
多留出一倍内存是最安全的。
重写AOF和RDB的进程(即使不做持久化,复制到Slave的时候也要写RDB)会fork出来一条心的进程。采用了操作系统的Copy-On-Write策略(如果父进程没被修改,子进程与父进程共享Page。如果父进程的Page被修改,会复制一份改动钱的内容给新进程),留意Console打印出来的报告。如‘RDB:1215MB of memory uesd by copy-on-writer’.
在系统季度繁忙时,设置vm.overcommit_memoory = 1,是的fork()一条10G的进程时,因为COW策略而不一定需要有10G的free memory。
当内存到达时,按照配置的Policy进行处理,默认policy为volatile-lru,对设置了expire time的进程LRU清除(不是按实际expire time)。如果没有数据设置了expire time 或者 policy为noeviction,则直接报错,但此时系统仍支持get之类的读操作。另外还有几种policy,比如volatile-ttl按最接近expire time的,allkeys-lru对所有key都做LRU。
>d **++Redis内存不是越大越好++**,千万不要有这种想法
如果内存过大,一旦出现问题,那将是灾难性的。
在主库宕机的时候,我们最常见的容灾策略为'切主'。具体为从该集群剩余从库中选出一个从库并将其升级为主库,该从库升级为主库再将剩余从库挂载至其下成为其从库。最终恢复整个集群结构。
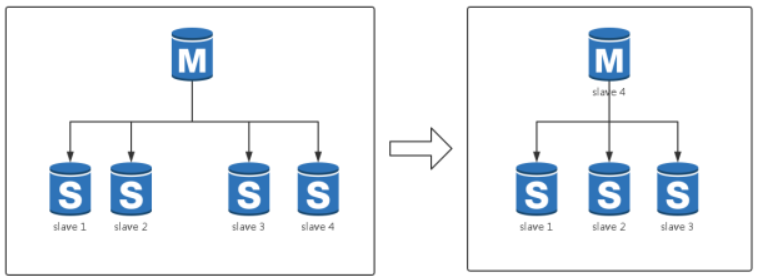
以上是一个完整的容灾过程,而代价最大的过程为从库的从新挂载,而非主库的切换。
整个从库重做流程是这样的:
- 主库bgsave自身数据到磁盘
- 主库发送rdb文件到从库
- 从库开始加载
- 加载完毕后续传,同时开始提供服务
很明显在这个过程中,Redis的内存体积越大以上每一个步骤的时间都会被拉长,试机测试的数据如下:
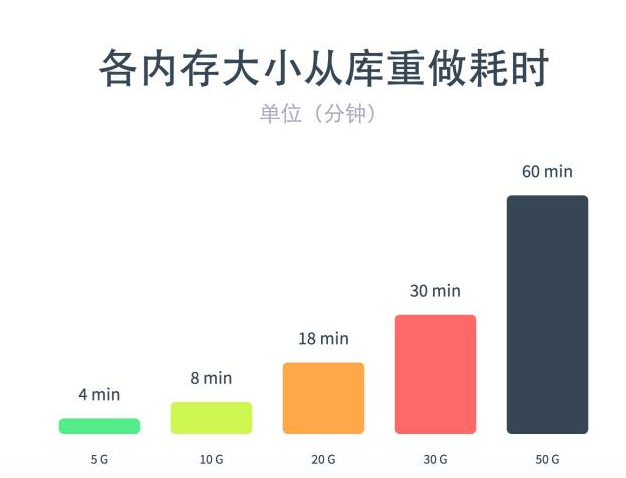
可以看到当数据达到20G的时候,一个从库的恢复时间已经被拉长岛了将近20分钟。如果10个从库那么如果一次恢复则工序200分钟。如果此时该从库承担着大量的读取请求。你能够认识这么长时间的恢复吗?
看到这里你肯定会问:为什么不能同时重做所有从库?这是因为所有从库如果同时像主库请求RDB文件,那么主库的网卡则立即跑满,从而进入一个无法正常提供服务的状态,此时主库又死了,简直雪上加霜。
当然,我们可以批量恢复从库,例如量量一组,那么全部从库恢复时间也减少了一半。这显然也不是根本的解决办法。
另一个重要问题在于第四点中。续传可以理解为mongodb的一个oplog,它是一个体积固定的内存空间,我们称之为“同步缓冲区”。
Redis主库的写入操作都会在改区域存放一份然后发送给从库,而如果上文中的1、2、3步耗时太久,那么很可能这个同步缓冲区就被重写,此时从库无法找到对应的续传位置,它会怎么办?但是重做1、2、3步!!!
但因为我们无法解决1、2、3步的耗时,因此从库永远进入恶心循环。不停的像主库请求完整数据,结果对主库的网卡造成严重的影响。
#### 扩容问题
很多时候会出现流量的突发性增长,通常在找到原因后,我们的应急做法就是扩容了。
但是根据上图中所属。一个20G的Redis扩容一个从库需要将近20分钟,在这个紧急的时刻20分钟业务能够容忍吗?可能还没扩容好,就挂了。
#### 网络不好导致从库重做最终引发雪崩
该场景的最大问题就是主库与从库的同步中断,而此时很可能从库仍然在接收写入请求,那么一旦终端时间过长同步缓冲区就很可能被重写。此时从库上一次同步的位置丢失,在网络恢复后,由于同步位置丢失,从库必须进行重做,上图中的1、2、3、4步,如果此时主库内存体积过大,速度就会很慢,而发送到从库的请求就会受到严重影响,同时由于传输的rdb文件体积过大,主库的网卡在相当长的一段时间内都会受到影响。
#### 内存越大,触发持久化的操作阻塞主线程的时间越长
Redis是单线程的内存数据库,在Redis需要执行好事的操作时,会fork一个新的进程来做,比如bgsave,berewriteraof,fork新进程时,虽然可共享的数据内容不需要复制,但会复制之前进程空间的内存页表,这个复制是主线程来做的,会阻塞所有的读写操作,并且随着内存使用量越来越大好事越长,例如:20GRedis,bgsave复制内存页表耗时大约在750ms左右,Redis主线程也会因为它阻塞750ms.
---
## 解决办法
1.设置过期时间
2.不存放垃圾到Redis中
3.及时清理无用数据
4.尽量对数据进行压缩
5.关注内存增长并定位大容量key
6.pika
### **++最后祈祷Redis永远不要异常。。。\\(\^o^)/~++**