📖 Q-learning
# Sarsa v.s. Q-learning
Sarsa:
- Sarsa is for training action-value function, $Q_\pi(s, a)$.
- TD target: $y_t=r_t+\gamma \cdot Q_\pi\left(s_{t+1}, a_{t+1}\right)$.
- We used Sarsa for updating value network (critic).
Q-learning:
- Q-learning is for training the optimal action-value function, $Q^{\star}(s, a)$.
- TD target: $y_t=r_t+\gamma \cdot \max _a Q^{\star}\left(s_{t+1}, a\right)$
- We used Q-learning for updating DQN.
# Q-learning (tabular version)
- Observe a transition $\left(s_t, a_t, r_t, s_{t+1}\right)$
- TD target: $y_t=r_t+\gamma \cdot \max _a Q^{\star}\left(s_{t+1}, a\right)$.
- TD error: $\delta_t=Q^{\star}\left(s_t, a_t\right)-y_t$.
- Update: $Q^{\star}\left(s_t, a_t\right) \leftarrow Q^{\star}\left(s_t, a_t\right)-\alpha \cdot \delta_t$.
# Q-learning (DQN version)
Approximate $Q^{\star}(s, a)$ by DQN, $Q(s, a ; \mathbf{w})$
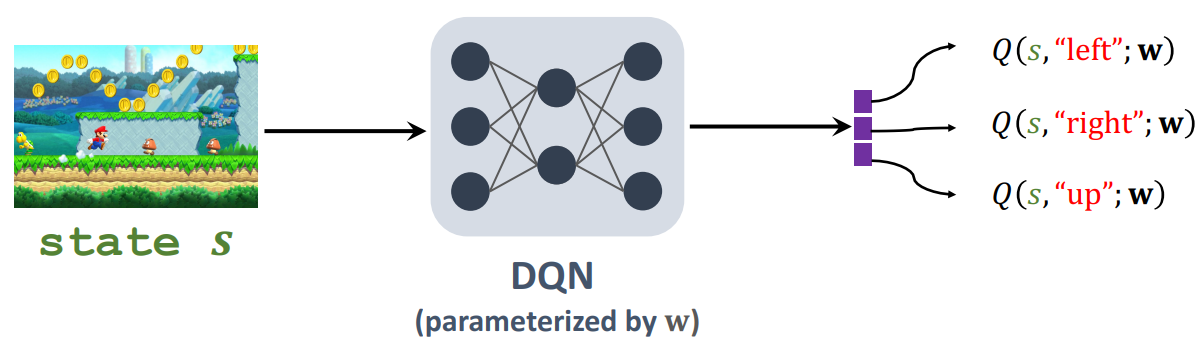
- DQN controls the agent by: 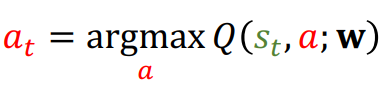.
- We seek to learn the parameter, w.
ALgorithm:
- Observe a transition $\left(s_t, a_t, r_t, s_{t+1}\right)$.
- TD target: $y_t=r_t+\gamma \cdot \max _a Q\left(s_{t+1}, a ; \mathbf{w}\right)$.
- TD error: $\delta_t=Q\left(s_t, a_t ; \mathbf{w}\right)-y_t$.
- Update: $\mathbf{w} \leftarrow \mathbf{w}-\alpha \cdot \delta_t \cdot \frac{\partial Q\left(s_t, a_t ; \mathbf{w}\right)}{\partial \mathbf{w}}$
# Derive TD-Target
- We have proved that for all $\pi$,
$$
Q_\pi\left(s_t, a_t\right)=\mathbb{E}\left[R_t+\gamma \cdot Q_\pi\left(S_{t+1}, A_{t+1}\right)\right] .
$$
- If $\pi$ is the optimal policy $\pi^{\star}$, then
$$
Q_{\pi^{\star}}\left(s_t, a_t\right)=\mathbb{E}\left[R_t+\gamma \cdot Q_{\pi^{\star}}\left(S_{t+1}, A_{t+1}\right)\right] .
$$
- $Q_{\pi^{\star}}$ and $Q^{\star}$ both denote the optimal action-value function.
**Identity 1**: $Q^{\star}\left(s_t, a_t\right)=\mathbb{E}\left[R_t+\gamma \cdot Q^{\star}\left(S_{t+1}, A_{t+1}\right)\right]$
The action $A_{t+1}$ is computed by

- Thus $Q^{\star}\left(S_{t+1}, A_{t+1}\right)=\max _a Q^{\star}\left(S_{t+1}, a\right)$
**Identity 2**: $Q^{\star}\left(s_t, a_t\right)=\mathbb{E}\left[R_t+\gamma \cdot \max _a Q^{\star}\left(S_{t+1}, a\right)\right]$

$\approx r_t+\gamma \cdot \max Q^{\star}\left(s_{t+1}, a\right)$ =TD target $y_t$
# Summary
- Goal: Learn the optimal action-value function $Q^{\star}$.
- Tabular version (directly learn $Q^{\star}$ ).
- There are finite states and actions.
- Draw a table, and update the table by Q-learning.
- DQN version (function approximation).
- Approximate $Q^{\star}$ by the DQN, $Q(s, a ; \mathbf{w})$.
- Update the parameter, w, by Q-learning.